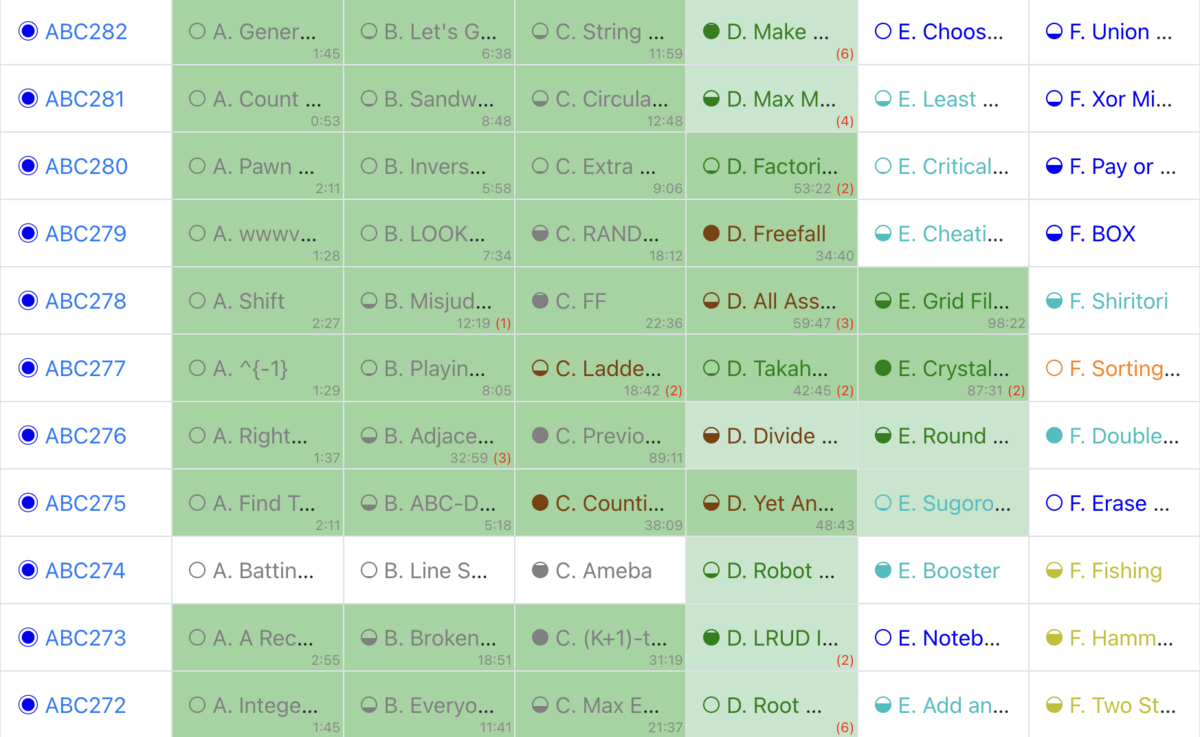
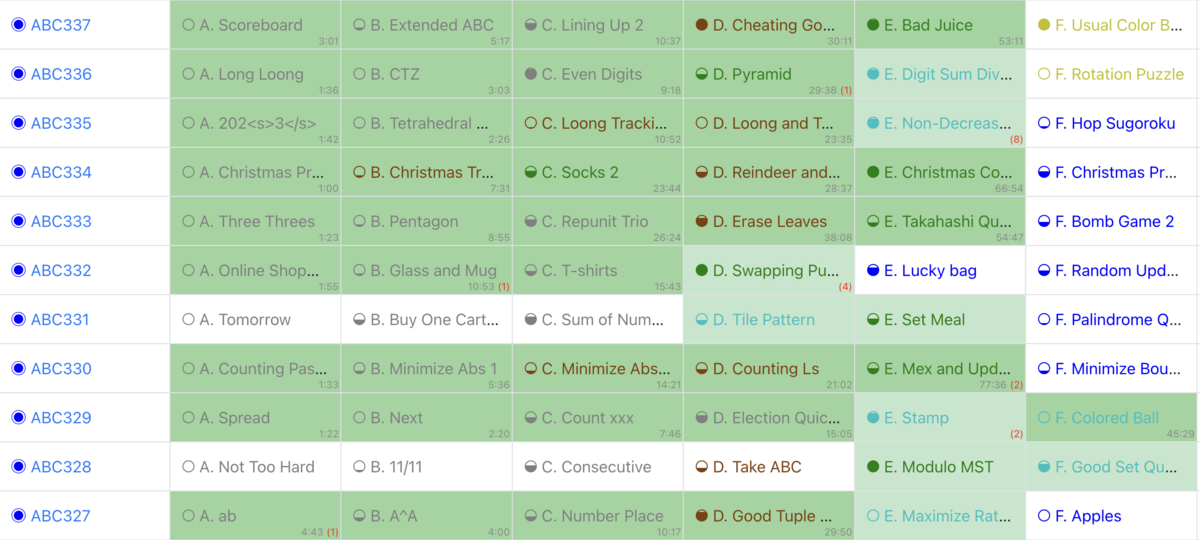
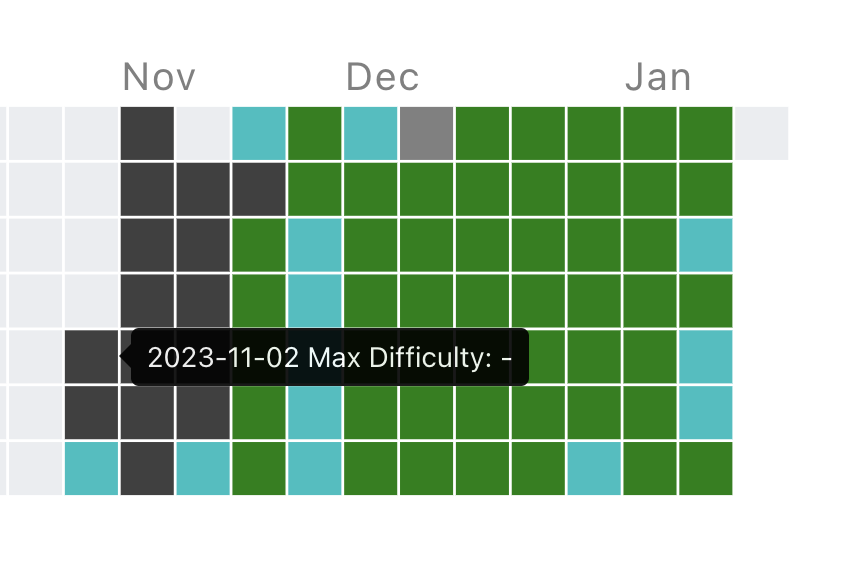
以前に水色(レート1200)を目指して1154まで行ったがその後レートが下がって挫折していた。11月あたりから再熱して地道に難易度緑の問題を毎日解き、8回コンテストに出てレート1113まで戻せた。数を解いていると解ける率が上がってきて楽しいので挫折するまで精進+コンテスト参加は続ける予定。今回こそは挫折前に水色まで行きたい、、、。
AtCoderの記録
from https://kenkoooo.com/atcoder/
別の選択肢としてAlexa → Home Bridge の連携をできるスキルがあった。しかし、有料化していたので今回は見送った。
After the initial 7 day trial period for new users, a monthly subscription costs $2.00 USD per month or an annual subscription costs $22.00 USD per year. Basically buying me a coffee once a month ( cheaper than a beer ).
https://www.homebridge.ca/faq
package main
import (
"flag""fmt""os""github.com/deepmap/oapi-codegen/pkg/middleware""github.com/labstack/echo/v4"
echomiddleware "github.com/labstack/echo/v4/middleware""github.com/yoshikipom/go/oapi/api"
)
func main() {
var port = flag.Int("port", 8080, "Port for test HTTP server")
flag.Parse()
swagger, err := api.GetSwagger()
if err != nil {
fmt.Fprintf(os.Stderr, "Error loading swagger spec\n: %s", err)
os.Exit(1)
}
swagger.Servers = nil
e := echo.New()
e.Use(echomiddleware.Logger())
e.Use(middleware.OapiRequestValidator(swagger))
ss := api.NewMyStrictServer()
h := api.NewStrictHandler(ss, []api.StrictMiddlewareFunc{})
api.RegisterHandlers(e, h)
e.Logger.Fatal(e.Start(fmt.Sprintf("0.0.0.0:%d", *port)))
}
動作確認
サーバサイド
yoshiki@yoshiki-mbp:go/oapi-codegen ‹main›$ go run main.go
____ __
/ __/___/ / ___
/ _// __/ _ \/ _ \
/___/\__/_//_/\___/ v4.10.2
High performance, minimalist Go web framework
https://echo.labstack.com
____________________________________O/_______
O\
⇨ http server started on [::]:8080
{"time":"2023-07-04T23:39:23.773179+09:00","id":"","remote_ip":"127.0.0.1","host":"localhost:8080","method":"POST","uri":"/pets","user_agent":"vscode-restclient","status":200,"error":"","latency":121657,"latency_human":"121.657µs","bytes_in":43,"bytes_out":41}






![[改訂3版]内部構造から学ぶPostgreSQL―設計・運用計画の鉄則 (Software Design plus)](https://m.media-amazon.com/images/I/51uD8h0R+4L._SL500_.jpg "[改訂3版]内部構造から学ぶPostgreSQL―設計・運用計画の鉄則 (Software Design plus)")



")
")
")




")
")

